The year is 2005 and AMD has the desktop performance crown. Intel needs to make a move to gain back ground. Their current Core series CPUs aren’t cutting it against the Athlon64 x2 series from AMD. Work is taking place behind closed doors to perfect the Core2 microarchitecture. With any advancement in performance you’d hope it would come without any implications in other areas but you’d be mistaken. If you haven’t educated yourself on the Spectre and Meltdown exploits then do so now.
https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html
https://www.youtube.com/watch?v=I5mRwzVvFGE
There are those who speculate that this recent bug might have something to do with spy agencies colluding with Intel in order to steal data or something. That’s cute to think but my bets are on the performance theory. There are a number of errata back in the Core2 era that are very similar to this exploit and might be the same.
AI18. Writing Shared Unaligned Data that Crosses a Cache Line without
Proper Semaphores or Barriers May Expose a Memory Ordering Issue Problem: Software which is written so that multiple agents can
modify the same shared unaligned memory location at the same time may
experience a memory ordering issue if multiple loads access this shared
data shortly thereafter.
Exposure to this problem requires the use of a data write which
spans a cache line boundary. Implication: This erratum may cause loads to be observed out of order.
Intel has not observed this erratum with any commercially available software or system. Workaround: Software should ensure at least one of the following is true
when modifying shared data by multiple agents:
to prevent concurrent data accesses.
with Inconsistent Memory Types may use an Incorrect Data Size or
Lead to Memory-Ordering Violations. Problem: Under certain conditions as described in the Software Developers Manual
section “Out-of-Order Stores For String Operations in Pentium 4, Intel Xeon,
and P6 Family Processors” the processor performs REP MOVS or REP STOS as fast strings.
Due to this erratum fast string REP MOVS/REP STOS instructions that cross
page boundaries from WB/WC memory types to UC/WP/WT memory types, may start
using an incorrect data size or may observe memory ordering violations. Implication: Upon crossing the page boundary the following may occur,
dependent on the new page memory type:
original data size.
original data size and there may be a memory ordering violation.
to UC, WP or WT memory type within a single REP MOVS or REP STOS instruction that will
execute with fast strings enabled.
Status: For the steppings affected, see the Summary Tables of Changes.
To further elaborate let’s again go back to before the Core2 launch.
AMD had the Athlon 64 x2 line and was kicking ass.
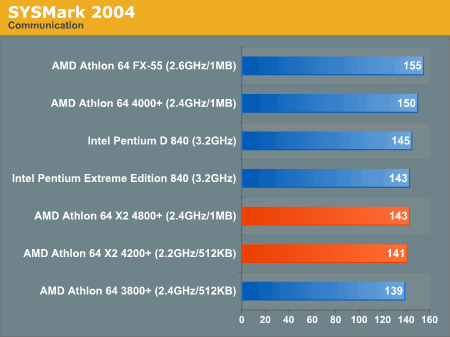
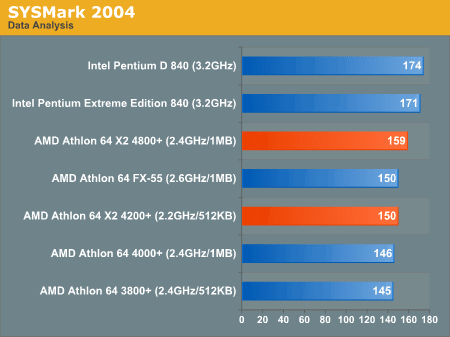
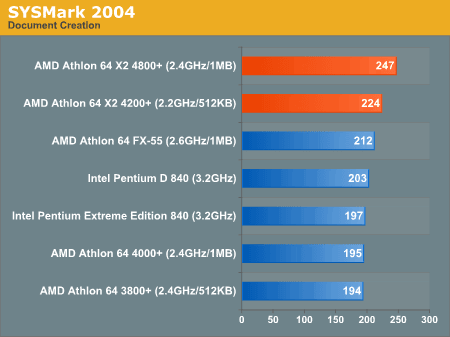
Performance from Intel wasn’t always 100% on top of the charts and that’s no good. Something was brewing at Intel and that thing was their cache performance. If Intel could predict code branches more effectively and use cache lines with a little less strict sense they could eek out that performance they needed. If security might be compromised a good way to misinform the public would be to tell programmers that they just need to change the way they do things from here on in. Maybe no one will look?
Cache performance has always been a thing that I praise Intel for. I’m very sure without that certain things wouldn’t be so performant when in comparison to AMD and Zen. People always use the term “Microarchitecture” improvements and never really expand on what that means. Maybe we get more special instructions or cores or “its just faster”. But back in the day this improvement I’m about to show you is pretty unreal.


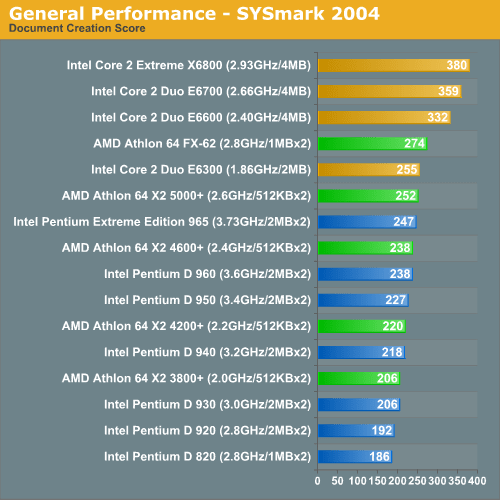
YAY back on top of the charts! But wait, what is this?

HOW MANY BUGS? Oh, but its way faster right? Yeah? Ok cool. Faster is great! But… bugs… exploits… and an underlying teaching of an industry of programmers to change how they operate. Intel has historically used their position to be a bully and use not so prudent methods of design in order to achieve performance that is unmatched.
How does AMD get away from this unscathed? They’ve been the good naïve kid at school that isn’t cheating or drinking or doing drugs.

There is another company that got wise to this and that is Qualcomm and their new Snapdragon 845 which has enhanced branch prediction and I assume it also doesn’t waste clock cycles on all this security checking nonsense. As you know, to be king you must gain performance at all costs.